
Der Unterschied zwischen Machine Learning und „klassischer“ Software
Posted by Julia Werner •
Einfache Einbindung: Online-Rechner für WordPress-Websites
Um einem potenziellen Interessenten bestimmte Fakten deutlich zu machen, sind Online-Rechner sehr hilfreich. Viele Agenturen programmieren hier extra etwas für den Kunden, anstatt auf professionelle WordPress-Plugins zurückzugreifen, die nur einen Bruchteil kosten und sehr viel können.
Der Interessent kann auf der WordPress Website seine Daten eintragen und bekommt sofort ein Ergebnis angezeigt. Für weitere Fragen ist direkt ein Button mit dem Hinweis “Kostenlose Erstberatung” eingebunden. Beim Absenden des Formulars werden die ausgefüllten Werte von WordPress aus direkt mitgeschickt.
Wie Edge Computer Anwendungen für KI massentauglich machen
Wie Edge Computer Anwendungen für KI massentauglich machen
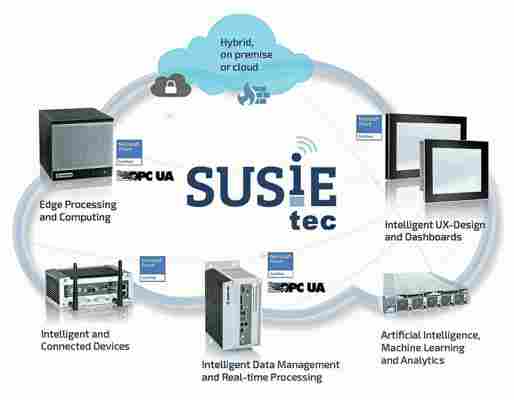
Mit dem IoT-Software Framework SUSiEtec von S&T Technologies kann Kontron Lösungen für Künstliche Intelligenz für seine Edge Computer aus einer Hand anbieten, so etwa für Visual Inspection.
KISS 4U V3 SKX: Der Server meistert High-End-Bildverarbeitung, SCADA/MES-Applikationen, AI und Machine Learning. (Bild: / Kontron)
Edge Computer erfüllen neben der Maschinensteuerung noch weitere wesentliche Aufgaben: Zum einen dienen sie als Gateways in das Netzwerk bis hin zum Internet. Und zum anderen können Embedded Computer direkt an der Maschine anspruchsvolle Aufgaben übernehmen, die in der Cloud aufgrund von Latenzzeiten und Bandbreitenbeschränkungen nicht erledigt werden können, etwa Anwendungen der Artificial Intelligence (AI; Künstliche Intelligenz (KI)).
Bei Visual Inspection werden Aufnahmen über eine Kamera, die entweder über USB oder Netzwerk angeschlossen ist, direkt auf dem Edge-Gerät von einem trainierten neuronalen Netz, im sogenannten Inference-Prozess, analysiert und ausgewertet, genauer als Menschen dazu in der Lage wären. Weitere Anwendungsmöglichkeiten für Computer mit Edge Performance sind Machine- und Deep-Learning, in deren rechenintensiven Prozessen zumeist vorgefertigte neuronale Netze trainiert werden, um dedizierte Anwendungen zu erfüllen. Dies Edge-seitig umzusetzen ist meist effizienter als zunächst Terabyte-weise Trainingsmaterial in die Cloud hochzuladen. Ein kompletter Prozess für Deep Learning besteht aus verschiedenen Phasen:
Samples sammeln,
Trainingsphase,
Gelerntes Netz transformieren,
Integration des trainierten Netzes in ein Produkt.
Trefferquote größer 80 Prozent gefordert
Nach den Kundenerfahrungen von S&T Technologies erwarten Kunden zumeist ein fertiges Produkt, beispielsweise wenn es um Objekterkennung geht. Ein „minimal viable product“, das also den Mindestanforderungen genügt, muss eine Trefferquote von mindestens 80% erreichen. Dabei sind die Anwendungsbeispiele vielfältig: So sollen Waagen im Supermarkt in die Lage versetzt werden, automatisch zu erkennen, welche Art Obst oder Gemüse abgewogen wird; Kunden müssen sich dann nicht mehr die dazugehörigen Nummern merken und von Hand eingeben. Angestellte an der Kasse müssen nicht mehr prüfen, ob der Kunde den richtigen Preis ermittelt hat.
Ein weiteres Beispiel: Bei der professionellen dauerhaften Haarentfernung mittels Laser beim Hautarzt kann das Gerät automatisch erkennen, auf welchen Hauttyp es sich einstellen soll. Eine aufwändige Untersuchung und Justierung durch den Arzt ist nicht mehr notwendig. Und bei Reparaturen und Instandhaltung reicht ein Foto des auszutauschenden oder defekten Teils, damit die Software oder App das Teil korrekt identifiziert und gegebenenfalls sofort die Bestellung des Ersatzteils auslöst.
S&T Technologies macht dabei oft die Erfahrung, dass Unternehmen bereits erprobte und bewährte Visual-Inspection-Systeme in Betrieb haben. Diese sind manchmal bereits weit über zehn Jahre im Einsatz und dadurch perfekt auf die Anwendung abgestimmt. Neue AI-Lösungen haben es naturgemäß schwer, sich gegen etablierte Systeme durchzusetzen. Oft fehlt inzwischen die Kenntnis einer effizienten Programmiersprache zur Entwicklung einer neuen Lösung.
Einfache Programmierung von AI-Anwendungen
Hier bietet das AI-Software Framework von SUSiEtec eine Alternative. Es erlaubt Entwicklern, die Learning- und Inference-Phase in den gängigen Sprachen .Net und Java unter Windows zu programmieren. Hardwareseitig zeigt sich, dass Embedded Computer für AI-Aufgaben ausreichend gerüstet sind, denn in der Praxis spielt die Auswertegeschwindigkeit oft nur eine geringe Rolle: Der Unterschied zwischen einer Zehntel und zwei Sekunden ist für die Anwendung oft nicht entscheidend. Kräftige Hardware-Beschleuniger wie Intels Movidius-Chips für neuronale Netze sind deshalb meistens in zeitkritischen Szenarien erforderlich, nicht aber in jeder Anwendung.
Neben Visual Inspection sind auch AI-Anwendungen in der Texterkennung und -Wiedergabe, der Audioerkennung und Verhaltensmustererkennung denkbar. Über die Audioerkennung lassen sich etwa ungewöhnliche Vibrationen identifizieren, die auf ein fehlerhaftes Maschinenteil hindeuten. So könnten etwa Züge „im Vorbeifahren“ geprüft werden. Firewalls in IT-Netzwerken werden über kurz oder lang „lernen“, was normales Verhalten im Netzwerk ist und bei als ungewöhnlich erkannten Aktivitäten Alarm schlagen oder sogar erste Schutz- und Abwehrmaßnahmen einleiten.
Software Framework SUSiEtec von S&T Technologies: realisiert die Vernetzung von IoT- und anderen Komponenten in Industrieumgebungen „from Edge to Fog to Cloud“. (Bild: S&T Technologies)
AI maßgeschneidert für alle Einsatzbereiche
Die Grundlagenforschung von vielen Internetkonzernen sowie aus den Universitäten wie Harvard und anderen Forschungsinstituten tut ihr Übriges zur Entwicklung von AI-Anwendungen. Auf dieser Basis können nun auch kommerzielle Unternehmen eigene Anwendungen umsetzen: Hier ist der Punkt, an dem Kontron mit S&T Technologies ansetzt. Sie ermöglichen ihren Kunden, sich auf ihre Kernkompetenzen zu konzentrieren und setzen State-of-the-Art-Technologien maßgeschneidert um, genauso wie es der Kunde benötigt, etwa die automatisierte Bildersuche einer Internetsuchmaschine.
Jetzt Newsletter abonnieren Verpassen Sie nicht unsere besten Inhalte Geschäftliche E-Mail Bitte geben Sie eine gültige E-Mailadresse ein. Abonnieren Mit Klick auf „Newsletter abonnieren“ erkläre ich mich mit der Verarbeitung und Nutzung meiner Daten gemäß Einwilligungserklärung (bitte aufklappen für Details) einverstanden und akzeptiere die Nutzungsbedingungen. Weitere Informationen finde ich in unserer Datenschutzerklärung. Aufklappen für Details zu Ihrer Einwilligung Stand vom 15.04.2021 Es ist für uns eine Selbstverständlichkeit, dass wir verantwortungsvoll mit Ihren personenbezogenen Daten umgehen. Sofern wir personenbezogene Daten von Ihnen erheben, verarbeiten wir diese unter Beachtung der geltenden Datenschutzvorschriften. Detaillierte Informationen finden Sie in unserer Datenschutzerklärung. Einwilligung in die Verwendung von Daten zu Werbezwecken Ich bin damit einverstanden, dass die Vogel Communications Group GmbH & Co. KG, Max-Planckstr. 7-9, 97082 Würzburg einschließlich aller mit ihr im Sinne der §§ 15 ff. AktG verbundenen Unternehmen (im weiteren: Vogel Communications Group) meine E-Mail-Adresse für die Zusendung von redaktionellen Newslettern nutzt. Auflistungen der jeweils zugehörigen Unternehmen können hier abgerufen werden. Der Newsletterinhalt erstreckt sich dabei auf Produkte und Dienstleistungen aller zuvor genannten Unternehmen, darunter beispielsweise Fachzeitschriften und Fachbücher, Veranstaltungen und Messen sowie veranstaltungsbezogene Produkte und Dienstleistungen, Print- und Digital-Mediaangebote und Services wie weitere (redaktionelle) Newsletter, Gewinnspiele, Lead-Kampagnen, Marktforschung im Online- und Offline-Bereich, fachspezifische Webportale und E-Learning-Angebote. Wenn auch meine persönliche Telefonnummer erhoben wurde, darf diese für die Unterbreitung von Angeboten der vorgenannten Produkte und Dienstleistungen der vorgenannten Unternehmen und Marktforschung genutzt werden. Falls ich im Internet auf Portalen der Vogel Communications Group einschließlich deren mit ihr im Sinne der §§ 15 ff. AktG verbundenen Unternehmen geschützte Inhalte abrufe, muss ich mich mit weiteren Daten für den Zugang zu diesen Inhalten registrieren. Im Gegenzug für diesen gebührenlosen Zugang zu redaktionellen Inhalten dürfen meine Daten im Sinne dieser Einwilligung für die hier genannten Zwecke verwendet werden. Recht auf Widerruf Mir ist bewusst, dass ich diese Einwilligung jederzeit für die Zukunft widerrufen kann. Durch meinen Widerruf wird die Rechtmäßigkeit der aufgrund meiner Einwilligung bis zum Widerruf erfolgten Verarbeitung nicht berührt. Um meinen Widerruf zu erklären, kann ich als eine Möglichkeit das unter https://support.vogel.de abrufbare Kontaktformular nutzen. Sofern ich einzelne von mir abonnierte Newsletter nicht mehr erhalten möchte, kann ich darüber hinaus auch den am Ende eines Newsletters eingebundenen Abmeldelink anklicken. Weitere Informationen zu meinem Widerrufsrecht und dessen Ausübung sowie zu den Folgen meines Widerrufs finde ich in der Datenschutzerklärung, Abschnitt Redaktionelle Newsletter.
Die gleichen neuronalen Netze kommen zum Einsatz, wenn eine AI-Anwendung von S&T Technologies Produkte kategorisiert. Ausgeführt und beschleunigt wird die Anwendung natürlich auf Hardware von Kontron. Grundsätzlich halten Kontron und S&T Technologies den Markt reif für skalierbare AI-Lösungen, da alle Komponenten quasi „von der Stange“ verfügbar sind. Zudem unterstützt die S&T-Gruppe ihre Kunden beim Einstieg in diese neue Technologie, mit dem IoT Software Framework SUSiEtec. Bei der visuellen Erkennung, als prominentes Beispiel, beinhaltet dies die Klärung der Hardware-Anforderungen, Auswahl und Integration von Open-Source-Modulen und -Paketen sowie die Kapselung komplexer Probleme, z.B. über Docker.
Durch diese enorme Komplexität ergeben sich beim Zusammenspiel oft viele kleine Probleme, die dann von Kontron gemeinsam im Verbund mit der S&T-Gruppe für die Kunden gelöst werden können. Der Kunde wird auf seiner gesamten Reise von der Beratung bis hin zu einem fertigen, maßgeschneiderten Produkt begleitet. Vielfältige AI-Einsatzmöglichkeiten sind heute nicht nur denk- sondern auch umsetzbar.
* Stefan Eberhardt verantwortet bei S&T Technologies in Augsburg das Business Development für Artificial Intelligence.
(ID:45946324)
Der Unterschied zwischen Machine Learning und „klassischer“ Software
Das Bild stammt von einer Präsentation auf der Google I/O 19 von zwei Vertretern des TensorFlow-Teams bei Google und es stellt eine perfekte Beschreibung von Machine Learning dar. (via)
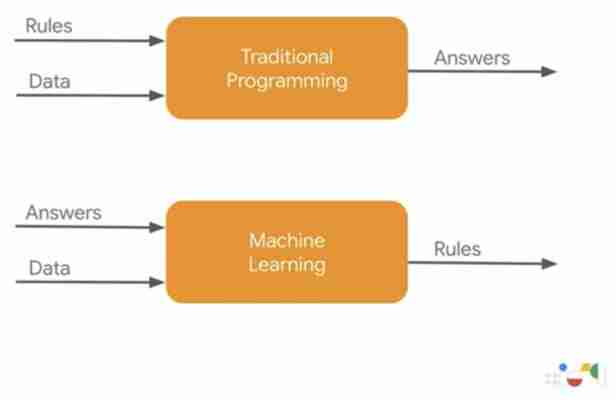
Software, wie wir sie bisher kannten, war grob so aufgebaut: Wir geben die Regeln (Algorithmen) ein, und die Software wendet diese Regeln auf die Daten ein, die wir einspeisen. Herauskommen die Antworten der Software.
Machine Learning dagegen ist ‚ungenauer‘. Wir füttern den Machine-Learning-Algorithmus mit ‚Antworten‘ in Form von großen Datenmengen, aus denen der Machine-Learning-Algorithmus sich eine Menge(!) an Regeln erarbeitet, die dann wiederum auf andere Datenmengen angewendet werden können. Auf diesem Weg können komplexe Regelwerke geschaffen werden, die nicht per Hand programmiert werden können.
Ein Beispiel: Wir füttern unsere lernende Maschine mit vielen Bildern von Katzen. Die Software lernt aus der Fülle der Bilder, wie Katzen aussehen können. Das wäre top-down, also mit hart einprogrammierten Regeln, schwierig zu realisieren. Zumindest wenn man möglichst akurat möglichst alle Katzen abdecken möchte.
Gleichzeitig kann hier auch einiges schief gehen, wenn man nicht auf das Learning Set achtet; also die „Antworten“ mit denen man den Machine-Learning-Algorithmus füttert. Wer dem Algorithmus beibringen will, wie Adler aussehen, sollte dabei nicht zu viele Bilder mit Adlern auf den Armen ihrer Halter zeigen, oder eine Regel ‚lautet‘ zwangsläufig dann quasi Vogel+Arm=Adler. Das ist, was man data bias nennt. (Hier etwa findet man sieben Formen von üblichen Fehlern bei der Datenauswahl.)
An diesem recht simplen Beispiel sieht man auch,
dass es nicht zwingend so ist, dass „mehr Daten“ zu akkuraterem Machine Learning führt. Es geht eher um „bessere Daten“. Also bessere Antworten zum Füttern. dass es einen Unterschied macht, wie präzise die Daten sind und etwa branchenübergreifende Übersetzungen von Machine-Learning-Erfolgen auf absehbare Zeit unrealisitisch sind.
Was heute mit Machine Learning erfolgreich gebaut wird, ist teilweise phänomenal, hat aber nichts mit allgemeiner künstlicher Intelligenz a la Skynet zu tun. Deshalb wird jeder gesellschaftliche Bereich, jede Branche, einen eigenen Weg gehen, ohne dass „Machine Learning als Sektor“ von einem Unternehmen dominiert wird. Man vergleiche den Einsatz von Machine Learning eher mit dem Einsatz von Datenbanken und Computern allgemein.
Machine Learning ermöglicht uns, Computer auf neue Aufgabenfelder anzusetzen. Neben Katzenbildern etwa Früherkennung von Krebs.
a16z-Analyst Benedict Evans schreibt auf Twitter:
We’re used to software that give yes/no answers – is there a match or not? Is this licence plate flagged? is that credit card valid? But ML doesn’t say yes/no. It says ‚maybe/maybe not/probably‘ answers. And, if you tell a cop or judge a ‚maybe‘ is a MATCH, bad things will follow
Aber damit einher geht auch ein gesellschaftlich notwendiges Umlernen wie wir Software und computergenerierte Ergebnisse bewerten. Es macht einen großen Unterschied, wenn Software nicht mehr nur Ja/Nein-Fragen mit ja und nein beantworten kann, sondern komplexere Sachverhalte mit ‚vielleicht/vielleicht nicht/wahrscheinlich‘ beantwortet.
Mehr noch, das muss sich zwingend in den User Interfaces widerspiegeln.
Machine Learning ist nicht ‚vorhersehbare‘ (überschaubare, nachvollziehbare) Mathematik wie es ‚klassische‘ Software ist. Machine Learning ist Stochastik, so wie wir Menschen Stochastik im Alltag verwenden. Auch wir können ein Tier sehen und es zunächst einer falschen Tiergattung zuordnen.
Der Unterschied liegt, auch hier, zwischen Bottom-up vs top-down. Mit allen Vorteilen und Nachteilen.
Es ist das Gleiche wie mit Plattformen mit user generated content und klassischen Medienorganisationen. Die Plattformen ermöglichen mehr, sehr viel mehr, als die klassischen Medienorganisationen, weil bottom-up ‚Überraschendes‘ nach oben kommen kann. Gleichzeitig kann auf diesem Weg anderes ’schief‘ gehen. Nichts ist perfekt.
Das beste Bild für Artificial Intelligence ist nach wie vor, Intelligence wie in Intelligence Service zu verstehen. Tiefe Einblicke, die man nur auf diesem Weg bekommen kann, die aber nicht automatisch fehlerfrei sind. Ganz im Gegenteil. Künstliche Intelligenz ist deshalb gar keine gute Beschreibung für Machine Learning et al. Denn es geht hier weniger um „Intelligenz“, was auch immer man darunter verstehen mag, und mehr um Einsichten, Ableitungen, Erkenntnisse.
(Siehe zum Thema auch meine kurzen Ausführungen in Der Tag 32 vom Juni diesen Jahres)
Tagged: